How to Evaluate Enterprise Service Desk Automation Platforms (Before You Buy)

Subscribe to receive the latest content and invites to your inbox.


The market for enterprise service desk automation platforms has matured, but the way most enterprises evaluate them hasn’t.
A lot of teams still start in the same place. They pull a shortlist from a review site, they compare pricing tiers, and sit through a few polished demos. Then, somewhere down the line, they realize they still haven’t answered the real questions that matter for their organization.
What happens when the environment gets complicated and messy?
What happens when automation has to span systems, teams, and edge cases?
What happens after go-live, when the real work starts?
Service desk automation isn’t something that you can easily swap out down the line. The platform you choose shapes how your IT organization operates: how fast incidents get resolved, whether your team can grow without adding headcount, and whether automation becomes a real asset or an expensive project you’re always catching up on.
This guide is for teams (IT leaders, operations managers, and CIOs) that want to evaluate these platforms more seriously. We’ll forgo the feature checklist and look at what holds up in production.
Why Most Evaluations Go Wrong
A bad platform decision tends to happen because the evaluation process itself steers a team towards the wrong signals.
They optimize for the demo, not the deployment.
Vendors build demos around their strengths. A platform can look completely seamless in a controlled environment and start showing its limits only after go-live, when ticket volumes spike, edge cases appear, and your team needs to build something the standard workflows don't cover.
They compare features instead of outcomes.
A feature list tells you what a platform has. It doesn't tell you what it actually changes. Two platforms can both claim AI-powered automation and deliver completely different results in production. One resolves 60% of tickets without human involvement. Another needs constant intervention to handle anything outside a narrow set of scenarios.
They underestimate the complexity ceiling.
Most platforms handle simple, repetitive automation reasonably well. The real question is what happens when things get hard. Multi-system workflows, hybrid environments, incidents that need conditional logic and coordination across teams. If your evaluation never pushes to that edge, you won't find out where the ceiling is until you've already hit it.
They leave key stakeholders out until it’s too late.
Service desk automation touches IT Ops, network operations, security, HR, and every business unit that depends on uptime. When evaluation is driven solely by procurement, the cross-functional performance questions don't get asked. That's where enterprise-grade platforms prove their worth.
They stop at the help desk.
Many traditional service desk automation platforms stop at the service desk. Network operations and security operations are left out entirely, handled by separate tools or manual processes that don’t talk to each other. For enterprises that need automation to work across domains (and not just the help desk queue) that gap can have operational consequences.
The Evaluation Framework: 10 Criteria To Assess Service Desk Automation Tools For Your Org
Not every platform approaches service desk automation the same way. Some are built around workflow rules inside a single system. Others extend further into orchestration, AI-assisted decisioning, or cross-environment execution. The goal of this framework is not to favor one label over another. It is to help you see which approach actually holds up in your environment, at your scale, under real operational pressure.
As you move through the vendor conversation, these are the questions and criteria you should be evaluating for your organization.
#1 Automation Logic: Static Rules, AI Assistance, or Adaptive Decisioning
Can it go beyond static rules? Rule-based systems work fine in stable, predictable environments. Enterprise IT isn't that. What matters is how the platform handles conditions it was not perfectly scripted for. Some systems rely on static rules. Some layer in AI assistance. Some can make more adaptive decisions in production. Your evaluation should test which model fits the complexity of your environment and how much human intervention it still requires when things change.
One approach worth scrutinizing closely is RPA, or robotics process automation. RPA automates at the UI layer, mimicking what a human does on screen rather than integrating at the system level. At the enterprise level, the distinction creates a maintenance burden that compounds over time. When an application updates its interface, RPA breaks. Someone has to go in and fix it.
API-level integration doesn’t have that problem. It’s more resilient because it connects directly to the system. It’s more auditable, more performant, and far better suited to the kind of dynamic, complex IT environments where real enterprise automation has to run. When evaluating any platform, it’s worth asking where the connection occurs and whether manual intervention is the fallback every time something breaks.
Ask: Can the platform handle an incident it's never seen before, without someone manually building a new workflow first?
#2 Orchestration Depth Across Hybrid Environments
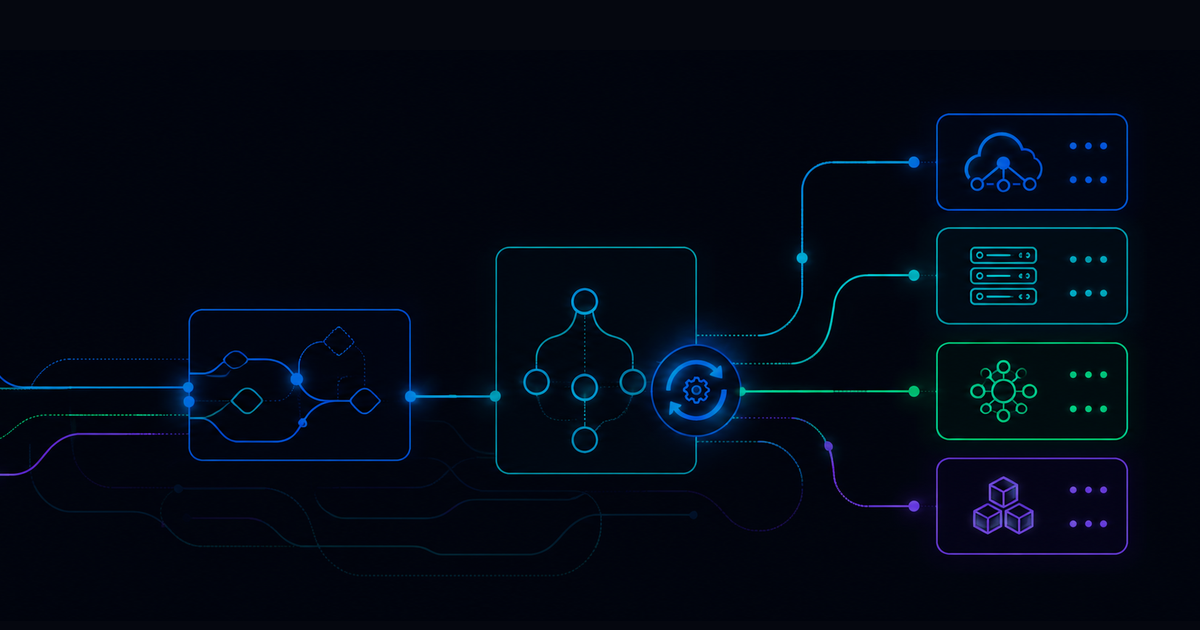
How well does it orchestrate across real environments? Automation that only works inside one system isn't really enterprise automation. It's task management with a better interface. Real orchestration means coordinating actions across cloud, on-prem, legacy systems, and third-party tools inside a single workflow without it showing. If it can't do that cleanly, you'll feel it every time something complex needs to run.
Ask: Show us a workflow that spans multiple systems and environments. What happens if one step fails halfway through?
#3 Breadth and Quality of Pre-Built Integrations
How deep are the integrations? Integration count alone doesn’t tell you much. Plenty of vendors have a long list of logos. The better question is how usable those integrations are in practice.
- Can your team actually build with them without constant workarounds?
- Are they maintained well?
- What happens when the third-party platform updates its API?
- Does your team end up doing the repair work?
For enterprise IT environments specifically, surface-level integrations aren’t enough. The platform needs to connect at the infrastructure and network layer too, through CLI, SNMP, and SSH. Without that depth, you’re automating at the edges of your environment while the core stays manual.
Shallow integrations create system drag. At first, it looks manageable. Later, it becomes one of the reasons the program slows down.
Ask: Which integrations are truly native, how often are they updated, and what does maintenance look like when connected systems change?
#4 Scalability From Day One to Full Enterprise Scale
Can it scale past the pilot stage? A platform that runs smoothly at 500 automations a month can look very different at 500,000. Don't evaluate for where you are now. Evaluate where your automation program realistically goes in three years. Migrating off a platform because it can't keep up is almost always more expensive than choosing the right one upfront.
Ask: What does your largest customer run in terms of monthly automation volume, and how does their infrastructure compare to ours?
#5 Self-Healing and Proactive Resolution
Can it resolve issues before tickets even exist? Reactive automation has value. If the system can kick in after a ticket is opened and reduce manual work, that matters.
But the more interesting question is whether the platform can detect, diagnose, and resolve issues before the ticket ever gets created. This is where the service desk starts shifting from a reactive support model to something more proactive and much more strategic.
A lot of vendors talk about this loosely. Ask to see something concrete.
The distinction worth pressing on is the difference between automated response and genuine self-healing. An automated response means the system reacts when something breaks. Self-healing means the platform is continuously monitoring, identifying drift or anomalies, and correcting before degradation becomes an incident. At enterprise scale, that difference is measured in uptime, in engineer hours, and in the kind of operational reliability that stops showing up as a line item in the post-mortem.
Ask: Can you show us a real example of the platform catching and resolving an incident before a ticket was ever generated?
#6 No-Code, Low-Code, and Bring-Your-Own-Code Flexibility
Does it work for different kinds of builders? Enterprise IT teams aren't built the same way. Some are deeply technical; others aren't and shouldn't need to be. A platform that locks everyone into the same build approach creates bottlenecks and frustration. What you want is a platform where a non-technical team member can build something useful, a developer can extend it later, and neither of them has to start over to do it.
Ask: Can a workflow built by someone without a technical background be picked up and extended by a developer without rebuilding from scratch?
#7 ROI Visibility and Automation Analytics
Can you prove value without building a separate case every quarter? Automation programs tend to lose momentum when the value is hard to show. That is especially true in large organizations where budgets get reviewed, priorities shift, and internal champions still have to justify expansion.
A strong platform should help surface the business case, not bury it. Teams should be able to see what is being deflected, what time is being saved, where bottlenecks remain, and what the next automation opportunities are. If that visibility is weak, the program often stalls even if the tech is decent.
Ask: How does the platform help us make the internal case for expanding automation investment over time?
#8 AI-Powered Ticket Deflection
How real is the ticket deflection story? Every vendor knows ticket deflection gets attention. The phrase shows up constantly because it should. A ticket that never gets created is cheaper, faster, and better for everyone involved. But this is another area where teams should push past the headline claim.
- How well does the virtual agent actually understand requests?
- How often does it resolve cleanly?
- How intelligently does it escalate when it should?
- And what do production numbers look like, not idealized ones?
There is usually a meaningful gap between what sounds good in the pitch and what happens in the first six months.
Ask: What's the average ticket deflection rate customers hit in the first six months, and what drives the difference between the high and low end?
#9 Security, Compliance, and Governance
At enterprise scale, automation is constantly touching sensitive systems, privileged credentials, and regulated data. The security model has to be as solid as the functionality. Role-based access controls, full audit trails, SOC compliance, governance frameworks — these aren't nice-to-haves. They're what make it possible to automate at scale without creating new exposure in the process.
This is also worth evaluating from a governance standpoint, not just a security one. As automation programs grow, the number of workflows touching regulated systems grows with them. A platform without strong governance tooling forces your team to build controls manually around the automation, which defeats much of the purpose. What you want is a platform where compliance is built into the workflow architecture itself, not bolted on afterward.
Ask: How does the platform manage privileged access inside automated workflows, and what does the audit trail look like when compliance comes knocking?
#10 Time-to-Value and Implementation Track Record
The most capable platform in the world doesn't help if it takes 18 months to actually run. Look at real deployment timelines from real customers, not projected ones. How fast does a proof of concept move? What does onboarding look like? How strong is the customer success model after the contract is signed? These are the signals that tell you what the relationship actually looks like once you're in it.
Ask: What does a typical enterprise deployment look like at 30, 60, and 90 days, and can we talk to a customer who went through it recently?
How To Pressure-Test a Platform Before You Buy
A strong demo won’t tell you how a platform will perform once it is live in your environment. Before you make a decision, push every vendor beyond the walkthrough and into the kind of complexity your team deals with every day.
You need to see whether the platform can handle workflows that cross systems, teams, approvals, and edge cases without falling apart. You also need to see what happens when a step fails halfway through — that's where the gaps show.
And if automation touches sensitive systems, governance, audit trails, and access controls can't be an afterthought. They need to be built to hold up under pressure.
What Good Looks Like in Practice
When a platform is strong across these areas, it stops being a tool and becomes infrastructure.
The service desk starts to operate differently. Engineers spend less time doing repetitive triage. Work moves faster. Resolution gets more consistent. The environment becomes less dependent on who happens to be available at that moment to clean something up manually. Over time, the organization starts to trust automation more because it is doing real work, not just creating another layer to manage.
Ask the teams that have gotten there how they'd describe it, and they won't say "we automated more things." They'll say the way IT operates has fundamentally changed. Problems get caught before they become incidents. Engineers work on things that matter. The business experiences IT as fast and reliable rather than something to work around. That's what a platform built for real enterprise complexity delivers when it's working the way it should.
That shift shows up in concrete numbers. Ticket deflection above 60%. Mean time to resolution in minutes, not hours. Automation programs that scale from a few hundred executions to millions without needing to be rebuilt. When evaluating enterprise service desk automation platforms, this is the standard worth holding every vendor to.
Resolve was built around exactly these criteria, and the production numbers show it.
Across our customer base, over 97 million automations run annually. Teams have recovered more than 8 million hours of operational time. Service desk ticket volumes drop by 90%, with 70% of that reduction visible in the first 90 days. MTTR improves by 99%. These aren't projections. They're production numbers from enterprises running real workloads at scale.
The agentic architecture acts on dynamic conditions and executes across the full orchestration complexity of a live enterprise IT environment. Predefined workflows are a starting point, not the boundary of what it can do. Our Automation Exchange gives IT operations teams over 5,000 prebuilt automations from day one, and RITA, our AI-powered virtual agent, resolves tickets instead of rerouting them to a manual review ticketing queue.
The enterprises running millions of automations daily didn't choose us because we were the easiest option. They chose us because their operational environments required a service desk automation platform built to that standard.
Ready to see how Resolve holds up against every point in this framework?
Bring your environment, your use cases, and your hardest questions. We'll take it from there.
.png)
.png)
